
Представьте ситуацию: воскресенье, вечер. Вы наконец-то решили посмотреть сериал, который откладывали три недели. И тут — звонок. Ведущий менеджер по продажам, голос слегка нервный: "Слушай, я тут спросил нашего нового AI-помощника про бонусы за квартал, а он вывалил мне полную ведомость зарплат всего IT-отдела. Это баг или фича?"
Холодный пот. Сериал можно выключать — ближайшие несколько часов вам не до него. И нет, это не фича. Это катастрофа, которая случается чаще, чем хотелось бы признавать.
Когда мы внедряем LLM-бота и подключаем его к корпоративным данным, мы часто забываем об одной неудобной правде: этот бот — идеальный "болтун". Он не злой и не хитрый. Он просто очень, очень услужливый. Если у него есть доступ к документу — он с радостью расскажет о его содержимом любому, кто вежливо попросит. Или хитро сформулирует вопрос. Или просто наткнется на нужную тему случайно.
Если ваш бот подключен к CRM и корпоративной базе знаний без жестких ограничений, вы буквально сидите на пороховой бочке. Ошибка в настройках доступа — это не просто "бот глючит". Это потенциальный канал утечки конфиденциальных данных: от зарплат коллег до условий контрактов с ключевыми клиентами. Давайте разберем, как выстроить систему защиты так, чтобы бот знал своё место и лишнего не болтал. Без паранойи, но с инженерной дотошностью.

1. Четыре способа "спалить контору" через бота
Прежде чем переходить к решениям, давайте посмотрим правде в глаза. Ниже — не теоретические страшилки из статей про "опасности ИИ". Это реальные случаи, с которыми сталкивались компании при внедрении AI-ассистентов. Имена и детали изменены, но суть историй — настоящая. И да, каждый из этих инцидентов можно было предотвратить правильной настройкой доступа.
"Бонусная" щедрость
Партнёры из Латинской Америки спросили у AI-ассистента про условия скидок. Бот услужливо выдал им размер бонуса, который действовал только для европейского рынка — и был на 15% выше. Индекс векторной базы был общим для всех регионов, фильтра по географии не существовало. Переговоры пришлось начинать заново.
Забывчивая чистка
Клиент попросил бота напомнить детали заказа. Бот не просто напомнил — он процитировал заметку оператора, где "для удобства" был сохранён полный номер банковской карты. PII-данные в поле notes никто не почистил перед индексацией. А ведь это прямое нарушение PCI DSS.
Финансы для всех
Стажёр отдела продаж спросил у бота: "Как у нас дела с выручкой?". Невинный вопрос — но бот выдал фрагменты из непубличной отчётности за Q3. Разработчики понадеялись на магическую фразу "не отвечай на вопросы о финансах" в системном промпте. Промпт не сработал, потому что сами документы лежали в общем индексе без ограничений.
Зомби-доступ
Менеджер уволился в пятницу. HR отключил почту, забрал пропуск, всё по процедуре. Вот только API-токен для AI-ассистента никто не отозвал. Ещё неделю бывший сотрудник мог задавать боту вопросы — и получать ответы с правами, которых у него уже не должно было быть. Классическая проблема: при offboarding-е забывают про интеграции.
2. Кто что видит: Матрица доступа "на пальцах"
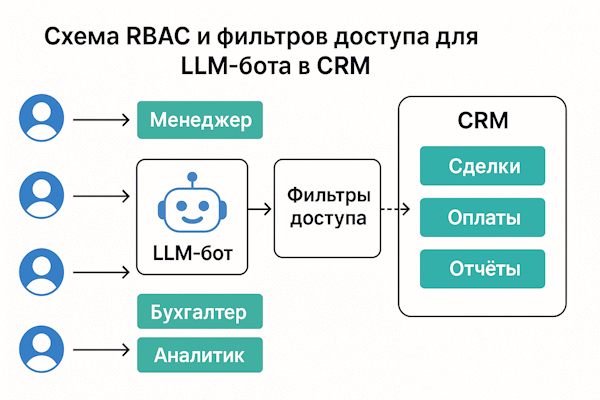
Окей, страшилки закончились. Теперь давайте разбираться, как это предотвратить. И первое, что нужно понять: ролевая модель бота должна быть зеркалом вашей CRM. Не нужно изобретать велосипед или придумывать какую-то особую "AI-иерархию". Используйте те же правила доступа, что уже работают для живых сотрудников.
Почему это важно? Потому что у вас уже есть готовая, продуманная система: кто-то имеет доступ к финансам, кто-то — только к своим клиентам, кто-то видит всё. Эти правила уже согласованы с безопасниками, юристами и бизнесом. Бот должен просто унаследовать их, а не получить какой-то отдельный "суперуровень".
Вот как это может выглядеть на практике:
| Роль | Зеленая зона (Можно) | Красная зона (Нельзя) | Техническая реализация |
|---|---|---|---|
| Sales | Свои сделки и клиенты в рамках региона, методички продаж, актуальные прайс-листы. | Финансовые прогнозы, сделки коллег из других регионов, персональные данные чужих клиентов. | Фильтр: owner_id == user.id OR region == user.region |
| Support | Тикеты из своей очереди, база знаний и FAQ, история обращений конкретного клиента. | Условия контрактов, зарплатные данные, материалы внутренних расследований. | Фильтр: queue == user.queue; исключить category == 'billing_internal' |
| Finance | Инвойсы, акты сверки, бюджеты подразделений, закрывающие документы. | Медицинские полисы сотрудников, черновики R&D, HR-документация. | Отдельный индекс (Index Isolation) — физическая изоляция данных. |
| Admin | Полный доступ ко всем данным и настройкам системы. | — | Обязательна двухфакторная аутентификация + детальное логирование всех действий. |
3. Архитектура "Секьюрити Гард" (Как это работает)
Теория — это хорошо, но как всё это работает на практике? Давайте разберём архитектуру по шагам. Я люблю аналогию с библиотекой: ваш бот — это библиотекарь, который умеет находить нужные книги. Но чтобы он не выдавал "секретные материалы" первому встречному, нужна система пропусков, охранник на входе и журнал учёта.
Вот как выглядит путь запроса от пользователя до ответа:
-
Шаг 1. Фейсконтроль (Идентификация)
Всё начинается с того, что мы точно знаем, кто перед нами. Пользователь авторизуется через SSO или OAuth — и система получает его
user_id, список ролей (roles) и границы доступа (scopes). Никаких анонимных запросов к боту — это первое железное правило. -
Шаг 2. Сбор контекста (Context Builder)
Прежде чем запрос уйдёт в обработку, система формирует "паспорт запроса". Из какого региона пользователь? К какому отделу относится? Какой у него грейд? Все эти атрибуты будут использоваться для фильтрации данных на следующем шаге.
-
Шаг 3. Умный поиск (Retrieval с фильтрами)
Вот здесь происходит магия безопасности. Когда бот ищет релевантные документы в векторной базе, он ищет НЕ "всё похожее на запрос", а "всё похожее, ГДЕ роль=Sales И регион=EMEA". Это называется pre-filter — жёсткий фильтр на уровне базы данных. Документы, не соответствующие критериям, физически не попадают в контекст LLM.
-
Шаг 4. Страховка (LLM Guardrails)
Даже если документ прошёл все фильтры, перед отправкой ответа пользователю срабатывает ещё один защитный слой. Специальный модуль проверяет: нет ли в ответе маркеров "CONFIDENTIAL"? Не просочились ли номера карт или паспортов? Это последняя линия обороны.
-
Шаг 5. Чёрный ящик (Аудит)
Каждый запрос логируется: кто спрашивал, когда, какие документы система подняла, что ответила. Если утечка всё-таки случится — вы сможете восстановить всю цепочку и найти "нулевого пациента". А ещё логи помогают выявлять подозрительные паттерны: например, если кто-то вдруг начал массово спрашивать про зарплаты коллег.
Обратите внимание: каждый шаг усиливает предыдущий. Это называется "defense in depth" — эшелонированная защита. Даже если один слой даст сбой, следующий подстрахует.
4. Где хранить "секреты": Сегментация данных
Есть старая мудрость: не кладите все яйца в одну корзину. В контексте AI-безопасности это означает, что ваша база данных для RAG (Retrieval-Augmented Generation) должна быть чётко структурирована. Чем лучше вы разделите данные на этапе хранения, тем проще будет контролировать доступ.
Вот три ключевых принципа сегментации:
- Изоляция индексов: Создайте отдельные "комнаты" для разных типов данных — например, отдельный индекс для B2B-клиентов и отдельный для B2C, разные индексы для разных регионов или бизнес-юнитов. Логика простая: проще вообще не пускать в комнату, чем следить за каждым шагом внутри. Если сейлз из России физически не имеет доступа к индексу европейских клиентов — никакой промпт-инжекцией эти данные не вытащить.
- Метаданные на каждом документе: При индексации каждый документ получает набор атрибутов — своеобразную "татуировку". Это как минимум
owner_id(кто владелец),region(география),data_class(public, internal или confidential). Правило железное: документ без меток для системы не существует. Лучше отклонить неразмеченный документ на этапе загрузки, чем потом разбираться с последствиями. - PII/PCI карантин: Персональные данные — номера карт, паспортов, телефоны — нужно обрабатывать ещё до попадания в базу знаний. Либо вырезаем их полностью, либо заменяем на токены (tokenization). Честно говоря, для понимания смысла документа LLM эти данные не нужны. "Клиент оплатил картой ****1234" работает ничуть не хуже, чем полный номер.
Хорошая сегментация — это инвестиция, которая окупается многократно. Вы не только снижаете риски, но и упрощаете себе жизнь при масштабировании: добавить новый регион или отдел — это просто создать новый индекс с правильными правилами.
5. Двойной заслон: Фильтры + Политики
Здесь я хочу развеять одно опасное заблуждение. Многие разработчики (и особенно менеджеры) думают: "Напишем в системном промпте 'Не отвечай на вопросы о зарплате' — и проблема решена!". К сожалению, это не работает.
Промпт-инструкции — это "мягкая сила". Они помогают, когда пользователь задаёт вопрос случайно или по незнанию. Но если кто-то целенаправленно хочет обойти запрет — он его обойдёт. Это называется Jailbreak, и в интернете полно инструкций, как это делать. Школьники справляются за пять минут.
Поэтому правильный подход — комбинировать несколько слоёв защиты:
| Слой защиты | Как это работает (для технарей) | Надежность |
|---|---|---|
| 1. Pre-filter (База данных) | Фильтрация на уровне запроса к векторной базе: WHERE role IN (...) AND region = .... Данные, не соответствующие критериям, физически не попадают в контекст LLM. Их как будто не существует. |
Высокая — обойти невозможно |
| 2. Post-filter (Код) | Дополнительная проверка метаданных найденных документов перед отправкой в LLM. Если в чанке обнаружена метка PII или CONFIDENTIAL — он удаляется из контекста. Страховка от ошибок разметки. | Высокая |
| 3. LLM Policy (Промпт) | Инструкция в системном промпте: "Если спрашивают про X, вежливо откажи". Работает для честных пользователей, но опытный атакующий может обойти через Jailbreak-техники. | Средняя — можно обойти |
Главное правило: никогда не полагайтесь только на промпт. Это последняя линия обороны, а не первая. Настоящая безопасность строится на уровне данных — там, где нельзя схитрить.

6. Чеклист для внедрения RBAC
Окей, вы прочитали всё это и думаете: "Звучит сложно, с чего начать?". Хорошая новость — базовую защиту можно настроить достаточно быстро. Не пытайтесь сделать всё идеально с первого раза. Начните с основ и итерируйте.
Вот примерный план действий:
- Этап 1. Матрица ролей: Сядьте с командой безопасности и составьте таблицу: какие роли есть в компании, кто к каким данным должен иметь доступ. Это фундамент всего остального. Без чёткого понимания "кто что видит" дальше двигаться бессмысленно.
- Этап 2. Разметка данных: Настройте ETL-пайплайн так, чтобы каждый документ при индексации получал нужные метаданные. Это техническая работа, но она окупится. Автоматизируйте всё, что можно — ручная разметка не масштабируется.
- Этап 3. Фильтрация: Реализуйте Pre-filter в поисковом запросе. Протестируйте: попросите коллегу из другого отдела задать боту вопросы про ваши данные. Он не должен ничего найти.
- Этап 4. Логирование: Подключите систему аудита. Каждый запрос должен записываться: кто, когда, что спросил, какие документы подняли. Elastic, Splunk, или даже простая база данных — главное, чтобы логи были.
- Этап 5. Red Teaming: Попросите своих же разработчиков (или внешних специалистов) попытаться "сломать" бота. Задача простая: вытащить данные, к которым у тестировщика не должно быть доступа. Это не паранойя — это здравый смысл.
- Этап 6. Пилот: Запустите бота на небольшой группе пользователей. Объясните им, что бот "видит", а что нет. Соберите обратную связь. Исправьте очевидные проблемы. И только потом — масштабируйте.
Важный момент: это не одноразовая настройка. Роли меняются, сотрудники приходят и уходят, появляются новые типы данных. RBAC — это процесс, а не проект.
7. Ответы на неудобные вопросы
Когда мы рассказываем клиентам про RBAC для AI-ботов, всегда возникают одни и те же вопросы. Вот честные ответы на самые частые из них — без маркетингового глянца.
Не уверены в безопасности вашего AI-решения?
Мы понимаем — разбираться во всём этом самостоятельно непросто. Если вы уже внедрили бота или только планируете, мы можем помочь: проведём аудит текущей архитектуры, найдём слабые места и настроим RBAC так, чтобы вы спали спокойно. Никаких утечек, никаких звонков в воскресенье вечером.
Обсудить аудит безопасностиЧто ещё почитать по теме
Если тема безопасности AI-систем вас заинтересовала, вот пара материалов, которые дополнят картину:
- Как следить за LLM: логи, метрики и аудит — подробнее о том, как настроить мониторинг и не пропустить подозрительную активность.
- RAG без прикрас: архитектура, которая реально работает — если хотите глубже понять, как устроен поиск по документам в LLM-системах.