
Представьте: пятница, вечер. Ваш AI-бот бодро закрывает продажи, команда уже разошлась по домам, а вы мысленно подсчитываете недельную конверсию. И тут — бац — главный LLM-провайдер «ложится». Или, что ещё коварнее, начинает отвечать с задержкой в 30 секунд. Клиенты видят крутящиеся спиннеры, поддержка захлебывается в тикетах, а вы... вы считаете упущенную выручку и думаете, как объяснить это руководству в понедельник. Знакомо? Это классический сценарий отсутствия катастрофоустойчивости.
Мы сами прошли через это не один раз. Помню случай, когда один из крупных LLM-провайдеров «прилёг» аккурат в разгар промо-акции нашего клиента. За два часа простоя бизнес потерял около 200 потенциальных заявок. После этого мы переосмыслили подход к архитектуре и теперь готовы поделиться выводами.
Даже лучшие модели — да, и GPT-4, и Claude, и Llama — иногда падают. Иногда они начинают галлюцинировать, выдавая абсолютно уверенные, но совершенно бредовые ответы. Иногда возвращают ответы в формате, который ломает ваш фронтенд (привет, неожиданный markdown в JSON-поле). Для бизнеса это не просто «технический сбой» — это прямой удар по NPS, репутации и деньгам. В этой статье мы разберем, как построить систему, которая продолжит работать (пусть и в упрощенном режиме), даже когда у вендора «пожар».
Для кого этот гайд: Для CTO, технических лидов и архитекторов, которые хотят спать спокойно, зная, что их бот не превратится в «кирпич» при первом же сбое API. А ещё — для всех, кто устал объяснять бизнесу, почему «умный бот» вдруг стал немым.
1. SLO/SLA: Обещаем только то, что можем гарантировать (с запасом)
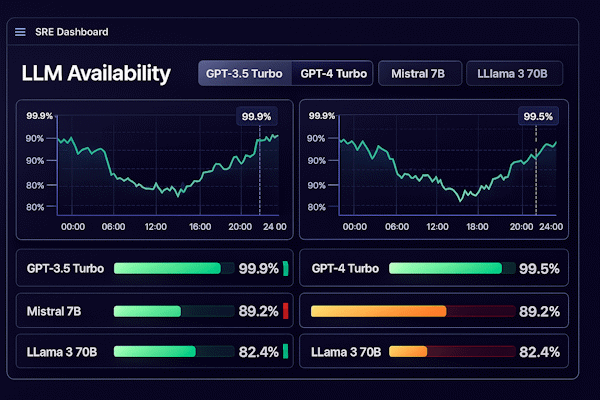
Одна из самых распространённых ошибок, которую мы видим у команд, впервые запускающих AI-бота в продакшн — это копирование SLA провайдера в свои договоры. Логика кажется простой: «OpenAI обещает 99.9% — значит, и мы можем». Но это ловушка.
Дело в том, что ваша система — это не только LLM. Это ещё и ваш бэкенд, база данных, сетевые соединения, CDN, интеграции с CRM и ещё десяток компонентов. Каждый из них добавляет свои риски. В теории вероятностей это называется «цепочка надёжности»: общая надёжность системы равна произведению надёжностей всех её компонентов. Если у вас пять систем по 99.9%, итоговая доступность уже 99.5%. А если какая-то интеграция работает на честном слове — считайте сами.
Поэтому золотое правило: ваша надёжность всегда ниже или равна надёжности самого слабого звена. И внешний SLA должен быть консервативнее внутреннего SLO — это ваш буфер для манёвра.
| Метрика (SLI) | Внутренняя цель (SLO) | Что обещаем клиенту (SLA) | Почему так |
|---|---|---|---|
| Доступность | ≥ 99.5% (допускаем ~3.6ч простоя в месяц) | 99.0% (оставляем себе буфер на форс-мажоры) | У LLM бывают «микро-штормы» доступности, которые трудно компенсировать мгновенно. |
| Latency (P95) | < 4 сек (генерация первого токена) | < 7 сек | Клиент готов ждать умный ответ, но до определенного предела. 7 сек — это уже "долго". |
| Точность (Accuracy) | < 1% галлюцинаций в knowledge-base | Best effort (юридически не гарантируем 100%) | Ни одна LLM не дает 100% гарантии фактов. Не подставляйте себя юридически. |
Совет: Всегда закладывайте «подушку безопасности» между вашим внутренним SLO и внешним SLA. Это ваше время на реакцию и переключение рубильников. Мы обычно рекомендуем разницу минимум в 0.5% — кажется мелочью, но в масштабе месяца это дополнительные часы на манёвр.
2. «Тревожные звоночки»: Когда пора бить тревогу
Самое неприятное в сбоях LLM — они редко происходят резко. Чаще система деградирует постепенно: сначала чуть вырастает время ответа, потом появляются редкие таймауты, затем ошибки становятся чаще... И вот вы уже в полноценном инциденте, хотя могли среагировать на полчаса раньше.
Не ждите полного падения с HTTP 500. К этому моменту ваши клиенты уже давно ушли к конкурентам. Лучше настройте алерты на ранние симптомы — те самые «тревожные звоночки», которые говорят: «Эй, что-то идёт не так, пора смотреть».
Вот на что стоит обратить внимание:
- Рост Latency: Если P95 вырос в 2 раза за 5 минут — это предвестник беды. Скорее всего, у провайдера забилась очередь, и скоро начнутся таймауты. Мы ставим алерт на рост P95 больше чем на 50% относительно скользящего среднего за час.
- Всплеск 429 (Too Many Requests): Вы уперлись в лимиты, или вендор без предупреждения снизил квоты. Бот скоро встанет. Кстати, такое бывает не только при перегрузке — иногда провайдеры меняют лимиты без уведомления, и вы узнаёте об этом постфактум.
- «Странные» ответы канареек: Это наш любимый приём. Запустите фоновый скрипт (канарейку), который раз в минуту спрашивает у бота что-то простое: «Сколько будет 2+2?» или «Назови столицу Франции». Если ответ пустой, слишком длинный или явный бред — модель «поплыла». Это ловит проблемы, которые не видны по HTTP-кодам.
- Отказ инструментов: Часто забывают, что бот — это не только LLM. Если CRM не отвечает, бот не может создать заявку. Для пользователя это выглядит как «бот сломался», хотя сама языковая модель жива и здорова. Мониторьте все интеграции отдельно.
Главный принцип: лучше получить ложный алерт и проверить, что всё в порядке, чем пропустить начало инцидента. Настройте пороги так, чтобы дежурный просыпался раз в неделю по ложной тревоге — это нормально. Но если алертов нет месяцами, вероятно, вы что-то пропускаете.
3. Режимы деградации: Не умирать, а упрощаться
Когда что-то идёт не так, у большинства ботов есть два состояния: «работает» и «упал». Но между ними — целый спектр промежуточных режимов, которые могут спасти ваш бизнес.
Представьте аварийное питание в здании: когда отключается электричество, лифты перестают работать, но свет в коридорах горит, а пожарная сигнализация продолжает функционировать. Никто не говорит, что здание «сломалось» — оно просто перешло в режим пониженного энергопотребления. С ботами должно быть так же.
Вместо того чтобы показывать пользователю унылое «Сервис недоступен», переводите бота в один из защитных режимов. Пользователь получит хоть какую-то пользу, а вы — время на восстановление.
1. Режим «Библиотекарь»
Отключаем генерацию ответов полностью. Бот ищет только по заранее заготовленной базе Q&A (FAISS, Elasticsearch или даже простой JSON). Это как справочник: спросили — нашли — показали. Работает молниеносно и никогда не выдумывает.
Плюс: 0% галлюцинаций, мгновенный ответ, нулевая нагрузка на LLM.
Минус: Нет эмпатии и гибкости, только сухие заготовленные ответы. Если вопроса нет в базе — бот честно скажет «не знаю».
2. Режим «Только чтение»
Бот может рассказать о статусе заказа, показать историю покупок, ответить на вопросы о товарах (все GET-запросы), но не может ничего изменить: ни оформить заказ, ни обновить данные, ни создать заявку.
Когда использовать: Если сломалась запись в БД, CRM лежит или есть проблемы с платёжным шлюзом. Лучше дать пользователю информацию, чем ничего.
3. Fallback на «Глупую, но быструю» модель
Если основная модель недоступна, переключаемся на более простую: GPT-4 → GPT-3.5, Claude → более лёгкая версия, или вообще на локальную Llama. Да, ответы будут менее «умными», но бот продолжит работать.
Важный нюанс: Разные модели по-разному понимают инструкции. Заранее подготовьте упрощённый системный промпт для резервной модели — без сложных цепочек рассуждений и хитрых форматов.
4. Эвакуация на человека
Последний рубеж: бот честно признаётся «Я сейчас испытываю технические трудности, соединяю с оператором». Иногда лучше сразу передать разговор человеку, чем мучить клиента глючным ботом.
Критически важно: Убедитесь, что у вас действительно есть свободные операторы в этот момент. Иначе вы просто перенесёте затор из бота в колл-центр, и клиент будет злиться вдвойне.

Какой режим выбрать? Зависит от того, что именно сломалось. Если проблема только с LLM — включайте «Библиотекаря» или fallback-модель. Если лежит CRM — переходите в «Только чтение». А если всё плохо и вы не понимаете, что происходит — честно эвакуируйте на людей, пока разбираетесь.
4. Политика переключения моделей (Model Swap)
Звучит просто: основная модель упала — включаем резервную. На практике всё сложнее. Нельзя просто взять и поменять модель на лету, как лампочку в люстре.
У каждой LLM свой «характер». Claude любит структурированные ответы, GPT иногда добавляет лишние пояснения, Llama может иначе интерпретировать инструкции. Если ваш промпт заточен под одну модель, на другой он может выдать совершенно неожиданный результат — например, JSON с другими ключами или текст вместо структуры.
Вот несколько правил, которые мы выработали на практике:
- Держите версии промптов под каждую модель: Не один универсальный промпт, а несколько: prompt_v1_gpt4, prompt_v1_claude, prompt_v1_llama. Система должна автоматически подтягивать нужный шаблон при переключении. Да, это дополнительная работа, но она окупается в первый же инцидент.
- Финансовый предохранитель: Вот история из жизни. Основная модель упала, система автоматически переключилась на резервную у другого провайдера. Всё работает, клиенты довольны. А через день приходит счёт — резервная модель стоила в 5 раз дороже, и за сутки набежало больше, чем за месяц обычной работы. Мораль: обязательно настройте лимит на бюджет резервной модели.
- Канареечный запуск: Не переключайте 100% трафика на резервную модель сразу. Сначала пустите 5%, посмотрите на метрики 5-10 минут, убедитесь, что ответы адекватные и формат не сломался. Только потом раскатывайте на всех. Это спасёт вас от ситуации «хотели как лучше, получилось как всегда».
5. Очереди: Эффект «Прихожей»
Знаете, что отличает хороший сервис от плохого в момент перегрузки? Коммуникация. Когда вы видите на сайте «Вы в очереди, время ожидания примерно 2 минуты», вы, скорее всего, подождёте. Это понятно, это честно, это даёт ощущение контроля. А если сайт просто висит с крутящимся спиннером — вы закроете вкладку через 30 секунд.
С ботами всё то же самое. Когда запросов больше, чем может обработать система, не нужно пытаться обслужить всех одновременно — это гарантированный путь к тому, что плохо будет всем. Вместо этого используйте очередь с обратной связью.
Как это работает на практике:
- Принимаем запрос мгновенно. Пользователь нажал «Отправить» — сразу получил 202 Accepted. Никаких зависаний.
- Ставим в очередь. Kafka, Redis, RabbitMQ — неважно. Главное, что запрос не потеряется и обработается в порядке очереди.
- Показываем статус. «Думаю...», «Анализирую ваш вопрос...» — что угодно, чтобы пользователь видел: система работает, а не зависла. Но не злоупотребляйте — бесконечный «Печатаю...» раздражает ещё больше.
- Предлагаем альтернативу при долгом ожидании. Если очередь большая и ожидание превышает 30-40 секунд, честно скажите: «Сейчас высокая нагрузка. Я могу ответить уведомлением, когда освобожусь, или перевести на оператора. Как удобнее?»
Этот подход называется backpressure — управляемое противодавление. Суть проста: лучше обслужить 80% клиентов качественно и быстро, а 20% честно попросить подождать, чем заставить страдать 100% пользователей от тормозящей системы.
Бонус: очередь даёт вам видимость. Вы можете посмотреть, сколько запросов ждут обработки, и понять масштаб проблемы. Без очереди вы узнаёте о перегрузке только когда клиенты начинают жаловаться.
6. Human in the Loop: Роль людей в хаосе
Когда всё горит, ваша первая линия поддержки — настоящие герои. Они принимают на себя весь негатив от клиентов, пока инженеры разбираются с проблемой. И ваша задача — дать им инструменты, чтобы они не чувствовали себя беспомощными.
Мы рекомендуем сделать в админке простой и заметный рубильник: «Включить режим ЧП». Одна кнопка, которую может нажать даже не-технический сотрудник. Никаких конфигов, никакого SSH — просто клик.
Что происходит при включении этого режима:
- Меняется приветствие бота: Вместо стандартного «Привет! Чем могу помочь?» пользователь видит: «Привет! Сейчас возможны небольшие задержки в ответах, но я постараюсь помочь». Честность снимает напряжение.
- Снижается порог переключения на оператора: Если раньше бот пытался три раза понять вопрос, теперь он после первой неудачи предлагает: «Давайте я переведу вас на специалиста». Лучше быстрый эскалейшн, чем долгие мучения.
- Отключаются тяжёлые сценарии: Сложная аналитика, длинные генерации, интеграции с медленными сервисами — всё это временно недоступно. Система работает в «лёгком» режиме, но работает.
И не забудьте про обратную связь для самих операторов. Простой чат или канал в Slack/Telegram, где дежурный инженер пишет: «Знаем о проблеме, работаем, ETA — 30 минут». Это снимает с поддержки необходимость гадать и придумывать ответы на вопросы «А что случилось?».
7. План инцидента: Действуем, а не паникуем
Три часа ночи, сработал алерт, вы продираете глаза и пытаетесь понять, что происходит. Это худший момент для того, чтобы принимать решения. Голова не работает, контекста нет, паника нарастает.
Именно поэтому всё должно быть прописано заранее. Runbook (книга инструкций) — это ваш друг в 3 часа ночи. Открыл, прочитал, сделал. Без раздумий, без созвонов, без «а давайте подумаем, что делать».
Вот как может выглядеть типичный таймлайн:
- Т+0 мин: Пришёл алерт в Slack/Telegram. Дежурный подтверждает: «Смотрю». Это важно — команда должна знать, что кто-то уже занимается проблемой.
- Т+5 мин: Первичная диагностика. Это сбой у нас или глобально у провайдера? Быстро проверяем status.openai.com, смотрим логи, оцениваем масштаб. Обновляем наш статус-пейдж.
- Т+10 мин: Принимаем решение о переключении. Если проблема на стороне провайдера и непонятно, сколько это продлится — включаем failover на резервную модель или переходим в режим деградации.
- Т+30 мин: Если проблема сохраняется — краткий статус в общий чат команды и для поддержки.
- Т+60 мин: Если затягивается — персональное уведомление ключевым B2B клиентам. Лучше они узнают от вас, чем от своих пользователей.
Главное правило: runbook должен быть написан так, чтобы его мог выполнить человек, который не спал всю ночь и вообще впервые видит эту систему. Никаких «очевидных» шагов, никаких предположений о контексте. Каждое действие — пошагово, с командами и ссылками.
8. Postmortem: Учимся на ошибках
Когда пожар потушен и все выдохнули, возникает соблазн забыть об инциденте как о страшном сне. Не надо так. Любой сбой — это болезненный, но ценный урок. Он подсвечивает слабые места, о которых вы, возможно, даже не догадывались.
Проведите постмортем — встречу по разбору инцидента. Но только без поиска виноватых. Серьёзно, это важно. Как только люди начинают бояться наказания, они перестают честно рассказывать, что произошло. А без честности вы не поймёте реальные причины.
Главный вопрос не «Кто уронил прод?», а «Почему система позволила это сделать?» Или ещё лучше: «Как сделать так, чтобы даже если Вася случайно уснул на клавиатуре и нажал Delete, всё продолжило работать?» Виноват никогда не человек — виновата система, которая позволила человеческой ошибке превратиться в инцидент.
Обязательные элементы хорошего постмортема:
- Хронология: Что произошло, когда и в какой последовательности. Факты, не интерпретации.
- Что сработало: Не забывайте отмечать, что пошло хорошо. Это мотивирует команду.
- Что не сработало: Где были пробелы в мониторинге, документации, процессах.
- Action Items: Конкретные задачи с ответственными и дедлайнами. Если после постмортема не появилось ни одной задачи в Jira — значит, вы просто поболтали.
И последнее: публикуйте постмортемы (хотя бы внутри компании). Это создаёт культуру открытости и помогает другим командам учиться на ваших ошибках.
Мини-FAQ для CTO
Собрали несколько вопросов, которые нам чаще всего задают на консультациях. Возможно, вы тоже об этом думали.
Подведём итоги
Катастрофоустойчивость — это не про «если что-то сломается», а про «когда что-то сломается». И чем раньше вы это примете, тем спокойнее будете спать.
Резюмируя всё вышесказанное, вот чек-лист для самопроверки:
- У вас есть внутренний SLO с запасом относительно внешнего SLA
- Настроены алерты на ранние признаки деградации (latency, 429, канарейки)
- Есть минимум 2 режима деградации (кроме «работает» и «упал»)
- Резервная модель протестирована и есть адаптированный промпт для неё
- Система очередей защищает от перегрузки
- Есть кнопка «Режим ЧП» для службы поддержки
- Runbook написан и регулярно обновляется
- Failover тестируется минимум раз в месяц
Если у вас сейчас нет и половины этих пунктов — не паникуйте. Начните с малого: настройте базовый мониторинг и создайте хотя бы один резервный режим. Остальное можно добавлять итеративно, по мере роста системы и бюджета.
Нужна помощь с отказоустойчивостью бота?
Мы уже прошли через десятки инцидентов и знаем, где обычно «стреляет». Поможем спроектировать архитектуру с резервными моделями, настроить мониторинг, написать runbook и провести первые учения. Обсудим вашу ситуацию на бесплатной консультации.
Записаться на консультацию