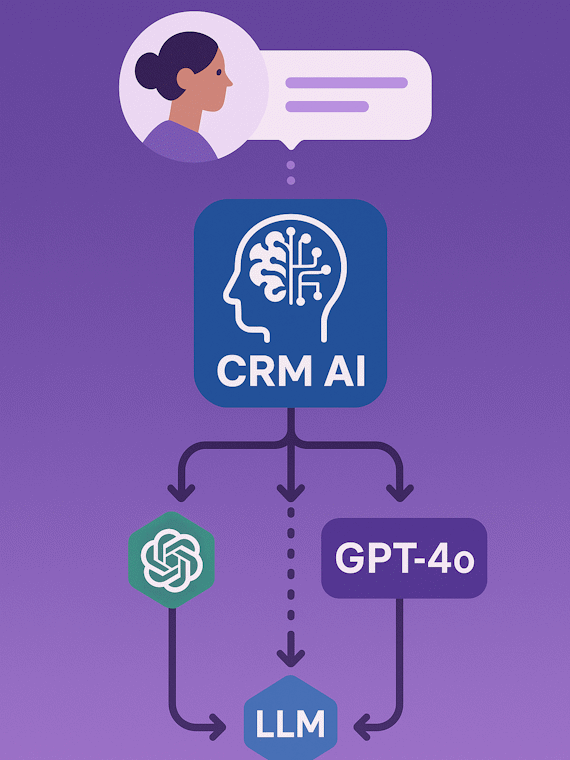
CRM AI анализирует контекст диалога и автоматически подключает нужный движок — от GPT-4o до локальных LLM.
Мы поддерживаем пул коммерческих и open-source моделей, следим за лимитами и скоростью отклика. Роутер проверяет намерение клиента, язык сообщения, требования по безопасности и стоимость, после чего направляет запрос в подходящий движок. Каждый новый сценарий проходит A/B-тестирование на реальных диалогах, а результаты сохраняются в витрине метрик, чтобы руководители видели, как меняется качество ответов и экономия токенов.
- Поддержка 12+ нейросетей и собственных fine-tune моделей.
- Интеллектуальное распределение по SLA: мгновенные ответы для чатов, вдумчивые — для аналитики.
- Экономия до 38% бюджета за счёт динамического выбора тарифов и агрегации запросов.
- Автоматическое переключение на fallback-модель и триггеры ручной проверки, если сценарий выходит за рамки допустимых рисков.
Время ответа < 1,8 секунды
за счёт параллельного прогрева моделей и балансировщика нагрузок.


Доставляем лучшие ответы клиенту, не выходя за бюджет
Сценарные политики
Для каждого сценария задаём правила: разрешённые модели, температурные настройки, требуемый тон коммуникации и уровни логирования. Дополнительно указываем KPI качества, а платформа автоматически подсказывает, когда сценарий требует пересмотра.
Контроль данных
Персональные данные обезличиваются, а передача в облачные модели ограничивается политиками Data Loss Prevention и журналируется. Отдельные потоки можно зашифровать ключами клиента, сохранив совместимость с требованиями ИБ.
Гибкая аналитика
Дашборды показывают распределение нагрузки по моделям, качество ответов и прогноз расходов, помогая планировать capacity. Видно, какие подсказки или источники знаний сильнее всего влияют на удовлетворённость клиентов.
Прозрачный путь запроса от клиента до ответа
Детектируем намерение
NLP-модуль определяет тему, язык, чувствительность и необходимую глубину ответа, сверяясь с корпоративными словарями и контекстом последних взаимодействий.
Подбираем модель
Правила роутинга учитывают лимиты API, стоимость токена и наличие приватных моделей. Если нужна эскалация, запрос автоматически отправляется в заранее подготовленную цепочку из нескольких LLM.
Обогащаем контекст
Ассистент подключает данные CRM, историю диалогов и готовые шаблоны, чтобы сократить галлюцинации. При необходимости он вызывает внешние инструменты: калькуляторы стоимости, регламенты или базы знаний.
Контролируем качество
Фильтр проверяет ответ на соответствие политике бренда и запускает человеческую проверку при необходимости. Параллельно система автоматически обучает классификаторы токсичности и фрод-паттернов.
97%
точности определения намерения после обучения на ваших данных и регулярного переобучения на новых диалогах
-32%
снижение затрат на токены за первый месяц использования благодаря гибридному стэку из коммерческих и open-source моделей
1,6s
среднее время ответа в активных чатах поддержки даже при пиковых нагрузках, за счёт авто-масштабирования и кэширования подсказок
Хотите увидеть оркестрацию на ваших сценариях?
Проведём аудит текущих диалогов, подключим модели и покажем сравнение качества ответов в течение двух недель.
